一、前言
在本文我们将以下面的例子带着大家去看看在实战中是如何运用的。
目标url:https://www.58pic.com/tupian/1272.html
二、数据分析
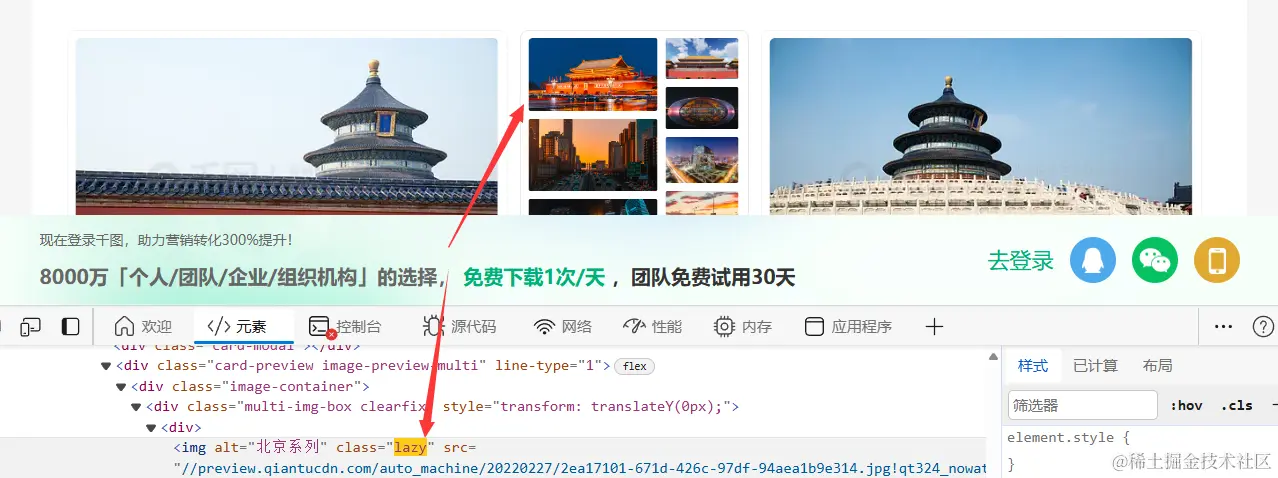
根据下图所示,图片被保存至img标签下,并且class值为lazy。当然这个网站除了lazy的img标签还有其他的(比如:class="lazy-bg-img"),这个可以自己想办法处理一下,如何去获取所有跟图片有关的img标签。
三、数据获取及展示
数据获取
'''
爬虫:
目标网站:https://www.58pic.com/c/27075257
任务需求:1、抓取第一页前36张图片 2、使用bs4解析
'''
import time
import requests
from bs4 import BeautifulSoup
class Image(object):
def __init__(self):
self.headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.62'
}
def parse_url(self,url):
print('开始分析')
resp = requests.get(url,headers=self.headers)
#print(resp.text)
if resp.status_code == 200:
soup = BeautifulSoup(resp.text,'lxml')
image_list = soup.find_all('img',class_='lazy-bg-img',limit=36)
#print(image_list)
for data in image_list:
title = data.get('alt')
# print(title)
print(f"开始下载 {title}")
img_url = 'https:'+data.get('data-original')
self.image_save(title,img_url)
else:
return None
def image_save(self,title,url):
resp = requests.get(url,headers=self.headers)
content = resp.content
with open('./img/'+title+'.jpg',mode='wb')as f:
f.write(content)
if __name__ == '__main__':
t = time.time()
url='https://www.58pic.com/tupian/1272.html'
image = Image()
image.parse_url(url)
print("总共耗时:",time.time()-t)
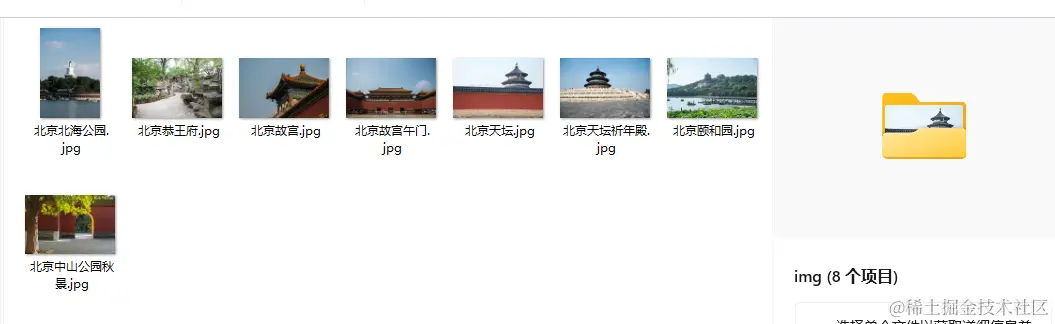
最终效果展示

四、结语
根据示例,我们会发现通过bs4解析可以很快速的根据标签的特殊性得到我们想要的数据。但要注意,有时候我们得到的响应内容会与F12打开看到的不同,所有在发现没有拿到数据的时候,请考虑我们得到的相应内容里面究竟是什么样子的。
到此这篇关于Python使用BeautifulSoup解析并获取图片的实战分享的文章就介绍到这了,更多相关Python BeautifulSoup获取图片内容请搜索IT俱乐部以前的文章或继续浏览下面的相关文章希望大家以后多多支持IT俱乐部!

