这篇只讲本项目里“PDF拆分”工具的功能层 JavaScript 实现。主流程可以概括为:
选择 PDF -> 读取页数 -> 生成拆分页组 -> 复制指定页面 -> 生成多个 PDF -> 单文件下载或 ZIP 打包下载
工具基于 Vue 组织交互状态,核心 PDF 操作使用 pdf-lib,多文件结果打包使用 JSZip,页面预览和书签读取由 pdfjs-dist 辅助完成。
在线工具网址:https://see-tool.com/pdf-split
工具截图:
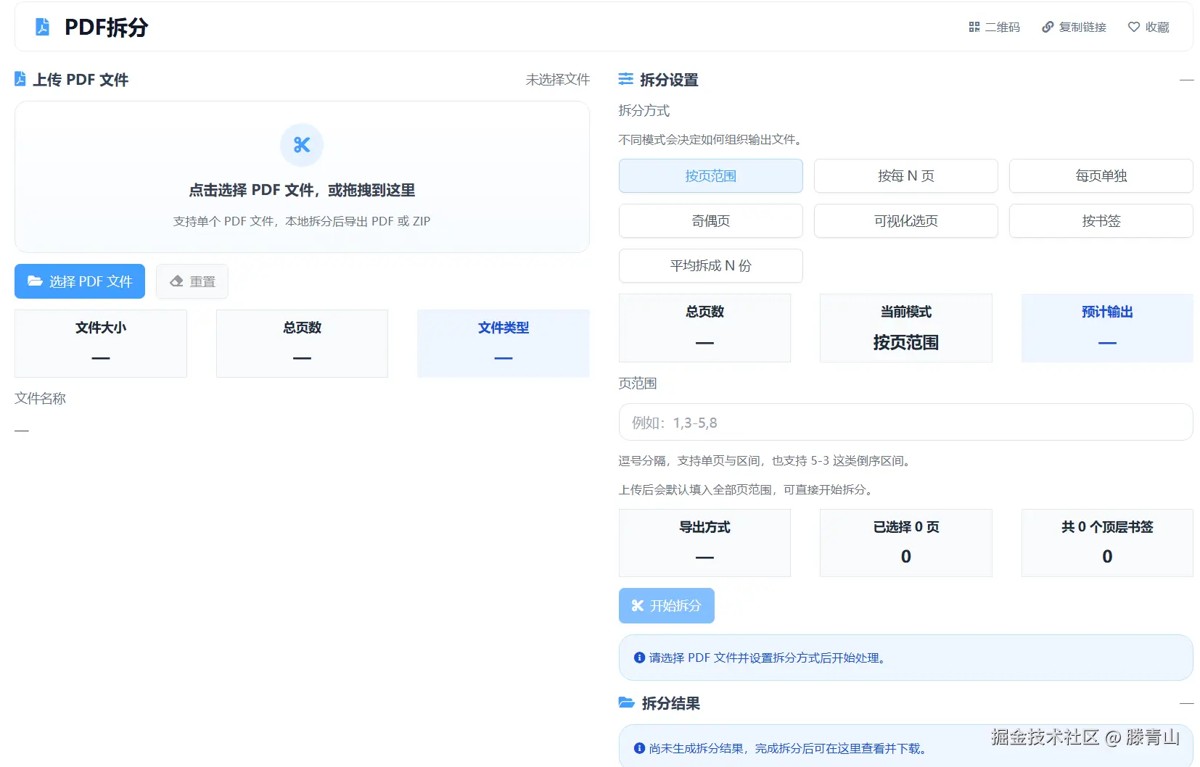
1. 文件进入流程前先做 PDF 判断
文件选择和拖拽上传共用同一套入口。真正加载前,先判断文件类型:
export function isPdfSplitFile(file) {
if (!file) {
return false;
}
var fileType = String(file.type || "").toLowerCase();
var fileName = String(file.name || "");
return fileType === "application/pdf" || /.pdf$/i.test(fileName);
}
这里同时判断 MIME 和文件后缀,是因为部分浏览器环境下 file.type 可能为空,只依赖 MIME 会误拦正常 PDF。
加载文件时,会把同一份原始字节切成两份用途:
var rawBytes = await file.arrayBuffer(); var splitBytes = rawBytes.slice(0); var previewBytes = rawBytes.slice(0); var sourceDoc = await PDFDocument.load(splitBytes);
splitBytes 用于后续拆分,previewBytes 用于预览和书签读取。这样拆分主链路和辅助信息链路互不影响。
2. 页码输入解析成统一的拆分页组
拆分逻辑不是直接处理输入框字符串,而是先转成统一结构:
{
label: "1-3",
indices: [0, 1, 2]
}
label 用于文件命名,indices 是 pdf-lib 需要的零基页码数组。
页码范围解析支持逗号分隔,也支持倒序区间:
function buildPageIndices(start, end) {
var indices = [];
var page;
if (start = end; page -= 1) {
indices.push(page - 1);
}
return indices;
}
所以用户输入 1-3,5,8-6 时,会生成三个输出段:第 1 到 3 页、第 5 页、第 8 到 6 页。
3. 多种拆分模式最终都归一到 groups
工具支持按页码范围、每 N 页、每页单独、奇偶页、可视化选择、书签、平均拆成 N 份。虽然入口不同,但最终都会变成 groups:
buildSplitGroups: function () {
if (this.splitMode === "ranges") {
return parsePdfSplitRangeGroups(this.rangeInput, this.totalPages);
}
if (this.splitMode === "everyN") {
return buildPdfSplitCountGroups(
this.totalPages,
parsePdfSplitPositiveInt(this.everyNInput),
);
}
if (this.splitMode === "everyPage") {
return buildPdfSplitEveryPageGroups(this.totalPages);
}
if (this.splitMode === "evenOdd") {
return buildPdfSplitEvenOddGroups(this.totalPages, this.evenOddMode);
}
if (this.splitMode === "visual") {
return buildPdfSplitVisualGroups(this.selectedPages);
}
if (this.splitMode === "bookmarks") {
return buildPdfSplitBookmarkGroups(this.bookmarkItems, this.totalPages);
}
if (this.splitMode === "nTimes") {
return buildPdfSplitNPartsGroups(
this.totalPages,
parsePdfSplitPositiveInt(this.nTimesInput),
);
}
return [];
}
这个设计的好处是,真正拆分 PDF 时不关心用户选择了哪种模式,只消费统一的页码分组。
4. 可视化选择会自动合并连续页
可视化模式下,用户点选的是离散页码。工具会先排序、去重,再把连续页合并成一个输出段:
export function buildPdfSplitVisualGroups(selectedPages) {
var uniquePages = Array.isArray(selectedPages)
? selectedPages
.map(function (page) {
return Number(page);
})
.filter(function (page) {
return Number.isInteger(page) && page > 0;
})
.sort(function (left, right) {
return left - right;
})
.filter(function (page, index, source) {
return index === 0 || page !== source[index - 1];
})
: [];
if (!uniquePages.length) {
throw createPdfSplitInputError("emptySelection");
}
var groups = [];
var start = uniquePages[0];
var end = uniquePages[0];
for (var i = 1; i
比如选择 1、2、3、7、9、10,结果会拆成 1-3、7、9-10 三个文件。
5. 书签拆分按顶层书签生成区间
书签模式先读取 PDF 的 outline,再把书签所在页转换成拆分区间。核心逻辑是:当前书签页作为开始页,下一个书签前一页作为结束页。
export function buildPdfSplitBookmarkGroups(bookmarks, totalPages) {
var normalizedBookmarks = Array.isArray(bookmarks)
? bookmarks
.filter(function (item) {
return (
item &&
Number.isInteger(Number(item.pageNumber)) &&
Number(item.pageNumber) >= 1 &&
Number(item.pageNumber) 1) {
groups.push({
label: "preface",
indices: buildPageIndices(1, normalizedBookmarks[0].pageNumber - 1),
title: "preface",
});
}
for (var index = 0; index
如果第一个书签不在第一页,前面的内容会单独生成一个 preface 分段。
6. 真正拆分 PDF 的核心是 copyPages
拆分主函数先构建 groups,然后每个分组创建一个新的 PDF:
for (index = 0; index
这里不是修改原 PDF,也不是切割二进制文件,而是把源文档里的指定页面复制到一个新文档。group.indices 决定当前输出文件包含哪些页。
7. 输出文件名根据拆分模式生成
文件名会先清理原 PDF 名称,再结合模式和页码标签生成:
export function buildPdfSplitOutputName(options) {
var config = options || {};
var baseName = safePdfSplitBaseName(config.baseName);
var index = Number(config.index) || 0;
var total = Number(config.total) || 0;
var label = String(config.label || "");
var mode = String(config.mode || "ranges");
var sequence = String(index + 1).padStart(3, "0");
var safeLabel = sanitizePdfSplitFileLabel(label) || sequence;
if (mode === "everyPage") {
return baseName + "_page_" + safeLabel + ".pdf";
}
if (mode === "bookmarks") {
return baseName + "_" + sequence + "_" + safeLabel + ".pdf";
}
if (total === 1) {
return baseName + "_split.pdf";
}
return baseName + "_split_" + sequence + "_p" + safeLabel + ".pdf";
}
这样拆出多个文件时,用户能从文件名看出顺序和页码范围。
8. 单结果直接下载,多结果打包 ZIP
导出时先判断结果数量。只有一个 PDF 时直接下载;多个 PDF 时放进 ZIP:
downloadResult: async function () {
if (!this.outputs.length) {
return;
}
if (this.outputs.length === 1) {
this.downloadOutput(this.outputs[0]);
return;
}
var zip = new JSZip();
this.outputs.forEach(function (item) {
zip.file(item.name, item.blob);
});
var zipBlob = await zip.generateAsync({
type: "blob",
compression: "DEFLATE",
compressionOptions: {
level: 6,
},
});
this.downloadBlob(zipBlob, "split_result.zip");
}
浏览器下载统一通过 Blob 和临时 a 标签完成:
downloadBlob: function (blob, filename) {
var url = URL.createObjectURL(blob);
var link = document.createElement("a");
link.href = url;
link.download = filename;
document.body.appendChild(link);
link.click();
document.body.removeChild(link);
URL.revokeObjectURL(url);
}
整个 PDF 拆分功能的核心,就是把不同输入方式都转换成稳定的页码分组,再用 pdf-lib 复制页面生成新文档,最后根据结果数量决定直接下载还是打包下载。
以上就是基于JavaScript实现在线PDF拆分工具的详细内容,更多关于JavaScript在线PDF拆分工具的资料请关注IT俱乐部其它相关文章!

