一. 前言
近期在研究 OCR 的一些工具 ,想着先试试本地识别 , 后面再尝试一下 AI 的效率,最后选出一个好点的 。
这一篇主要是了解了一下 paddleocr 的使用。
二. 安装启动
官方使用文档 :github.com/PaddlePaddle/PaddleOCR/blob/main/README_cn.md
环境准备
我这里使用的是 Anaconda 建的虚拟环境 ,以下可以跳过
conda create –prefix “D:codepythonenviromentpdf_env” python=3.11.9
conda activate “D:codepythonenviromentpdf_env”
Anaconda
# 安装基础组件 pip install PyQt6 pip install PyQt6-WebEngine pip install PyQt6-Frameless-Window pip install PyQt6-Fluent-Widgets -i https://pypi.org/simple/ # 安装 paddleocr pip install paddleocr # 安装 paddlepaddle (这里为了避免性能要求高,所以采用CPU 版本) # 另外还有性能更好的 GPU 版本 -> https://www.paddlepaddle.org.cn/install/quick python -m pip install paddlepaddle==3.1.0 -i https://www.paddlepaddle.org.cn/packages/stable/cpu/ # 安装 PyMuPDF 用于处理 PDF pip install PyMuPDF
运行项目 (CPU )
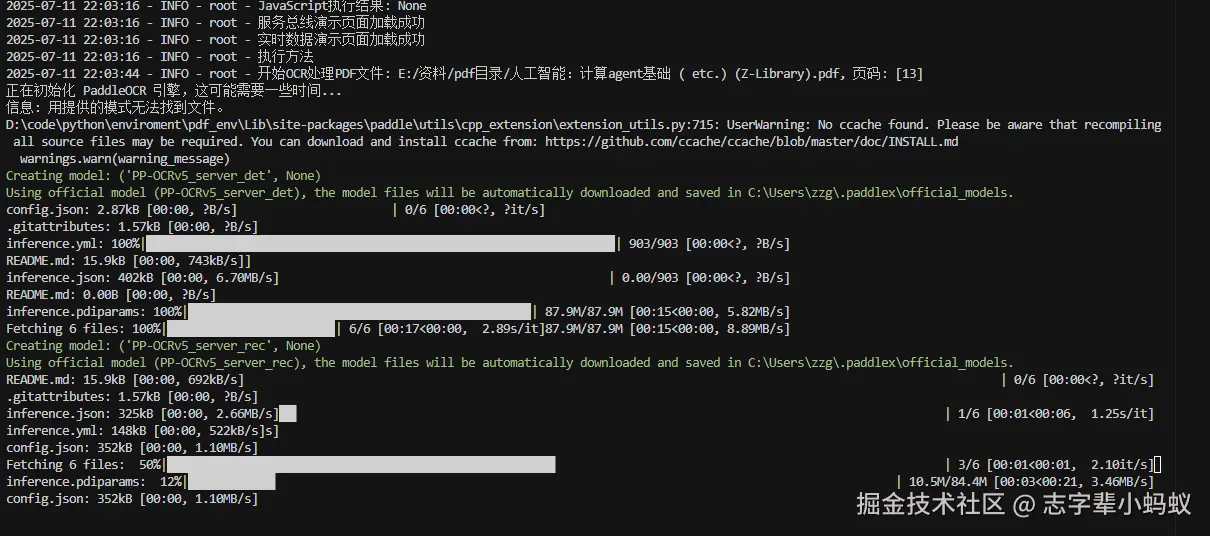
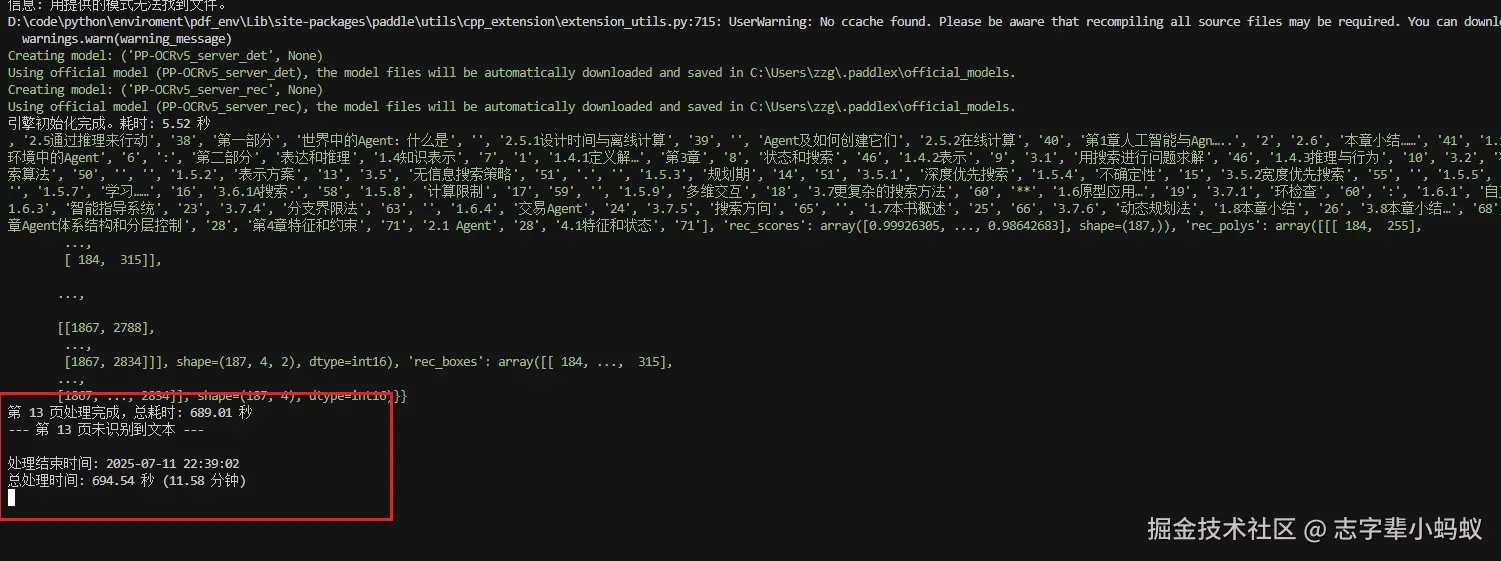
结果是出来了 ,但是这性能太吓人了 ,我这 CPU 也不算差呀
换个 GPU 试试
python -m pip uninstall paddlepaddle
查看自己的版本(Windows 版本)
nvidia-smi
安装对应版本
python -m pip install paddlepaddle-gpu==3.1.0 -i https://www.paddlepaddle.org.cn/packages/stable/cu126/
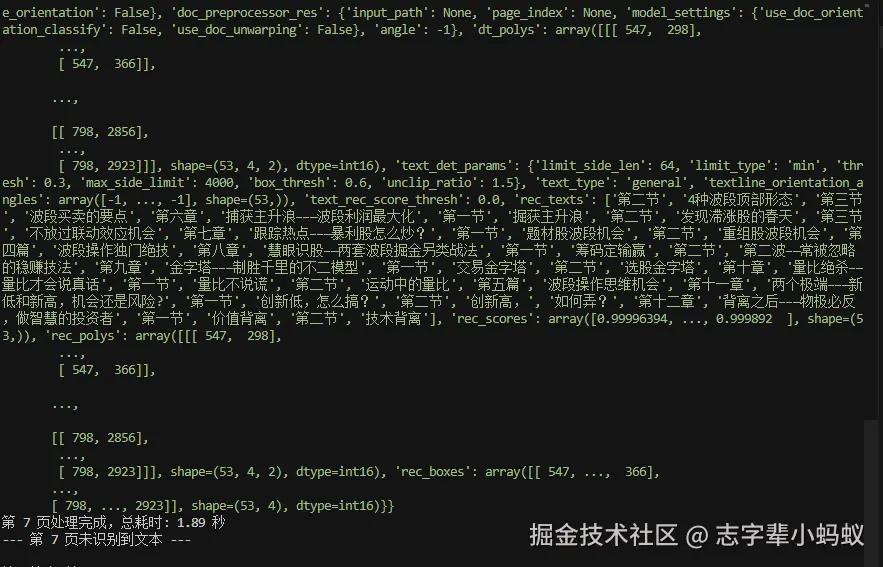
三. 核心代码
import os
import fitz # PyMuPDF
from paddleocr import PaddleOCR
import time
from datetime import datetime
from prettytable import PrettyTable
import csv
import traceback
import logging
import json
# 配置日志
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s',
handlers=[
logging.FileHandler("ocr_service.log"),
logging.StreamHandler()
]
)
logger = logging.getLogger("OCR_Service")
def ocr_pdf_pages(pdf_path: str, page_numbers: list[int], output_dir: str = None):
"""
使用 PaddleOCR 对 PDF 文件的指定页面进行 OCR,并将结构化结果统一导出到 CSV。
Args:
pdf_path (str): PDF 文件的路径。
page_numbers (list[int]): 需要读取的页码列表 (例如 [1, 3, 5])。
output_dir (str, optional): 输出结果的目录。如果指定,将保存图片、JSON 和汇总的 CSV 文件。
"""
start_time = time.time()
start_datetime = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
logger.info(f"开始处理时间: {start_datetime}")
if not os.path.exists(pdf_path):
logger.error(f"错误:找不到 PDF 文件 '{pdf_path}'")
return
# 初始化 PaddleOCR 引擎
logger.info("正在初始化 PaddleOCR 引擎,这可能需要一些时间...")
ocr_start_time = time.time()
ocr = PaddleOCR(
# --- 核心功能与模型设置 ---
lang="ch", # 1. 语言:指定为中文模型('ch' 支持中英文和数字)
ocr_version="PP-OCRv5", # 2. 模型版本:使用先进的PP-OCRv5
use_angle_cls=False, # 3. 方向矫正:自动检测文字方向并旋转图片
# device="gpu:0", # (新版推荐) 这是更现代的写法,指定使用0号GPU
use_tensorrt=False, # 5. TensorRT加速:在NVIDIA GPU上获得极致性能 (需提前安装TensorRT)
precision='fp16', # 6. 精度:使用半精度(fp16),速度更快,显存占用更低 (需要GPU支持)
# --- 性能与设备优化 (CPU用户) ---
enable_mkldnn=True, # 7. MKLDNN加速:若在CPU上运行,此选项可提升Intel CPU的性能
cpu_threads=6, # 8. CPU线程数:在CPU模式下运行时使用的核心数
# --- 效果微调 ---
text_rec_score_thresh=0.5, # 9. 识别阈值:只返回置信度高于 0.5 的识别结果,过滤掉模糊的猜测
)
ocr_end_time = time.time()
logger.info(f"引擎初始化完成。耗时: {ocr_end_time - ocr_start_time:.2f} 秒")
# 如果指定了输出目录,确保它存在
if output_dir:
os.makedirs(output_dir, exist_ok=True)
# 初始化列表以保存所有页面的数据,用于最后统一导出
all_csv_rows = []
csv_header = ['page', 'text', 'score', 'x_min', 'y_min', 'x_max', 'y_max']
try:
# 打开 PDF 文件
doc = fitz.open(pdf_path)
# 遍历指定的页码
for page_num in page_numbers:
page_start_time = time.time()
# 验证页码是否在有效范围内 (fitz 从 0 开始索引, 用户输入从 1 开始)
if not (1
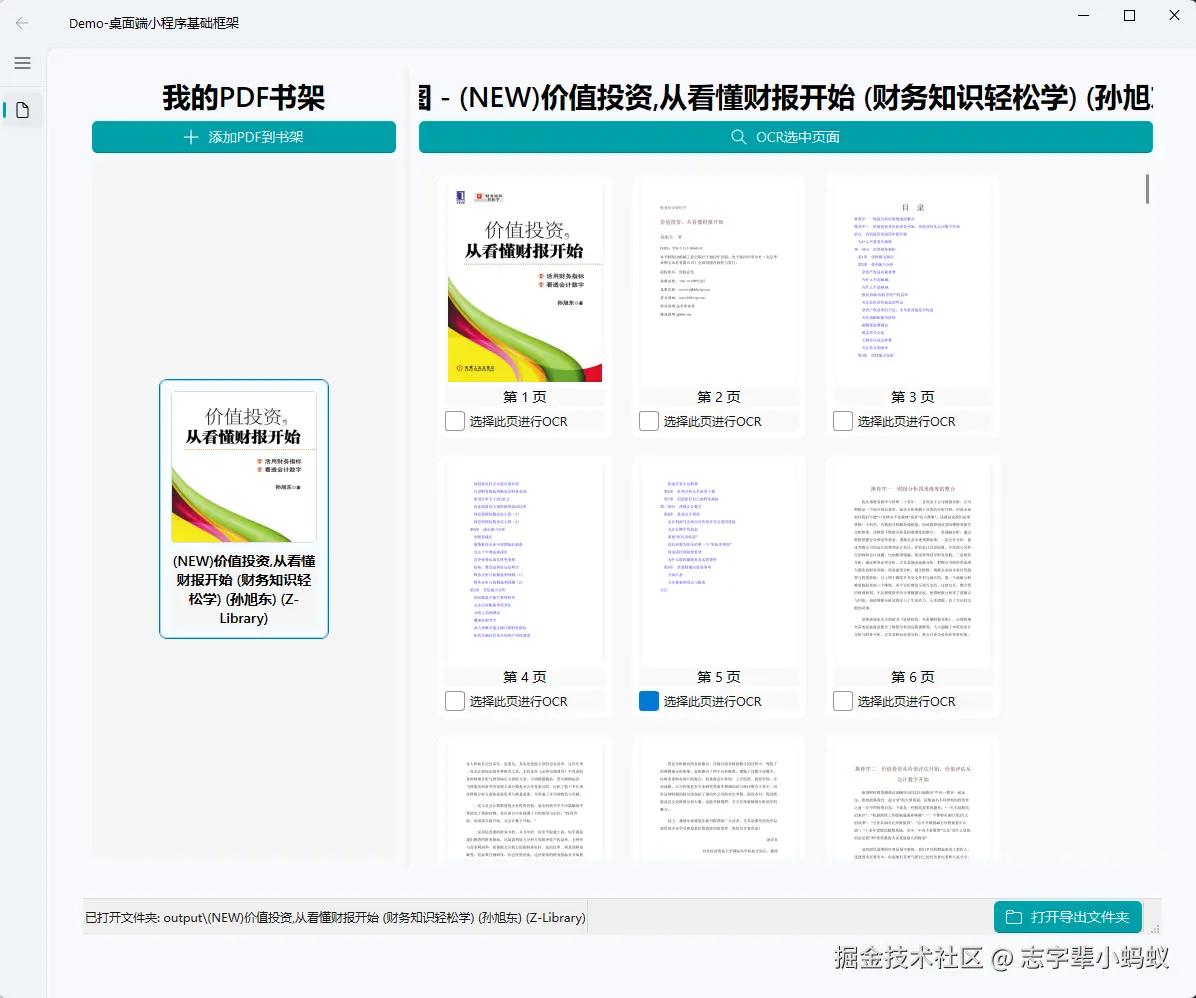
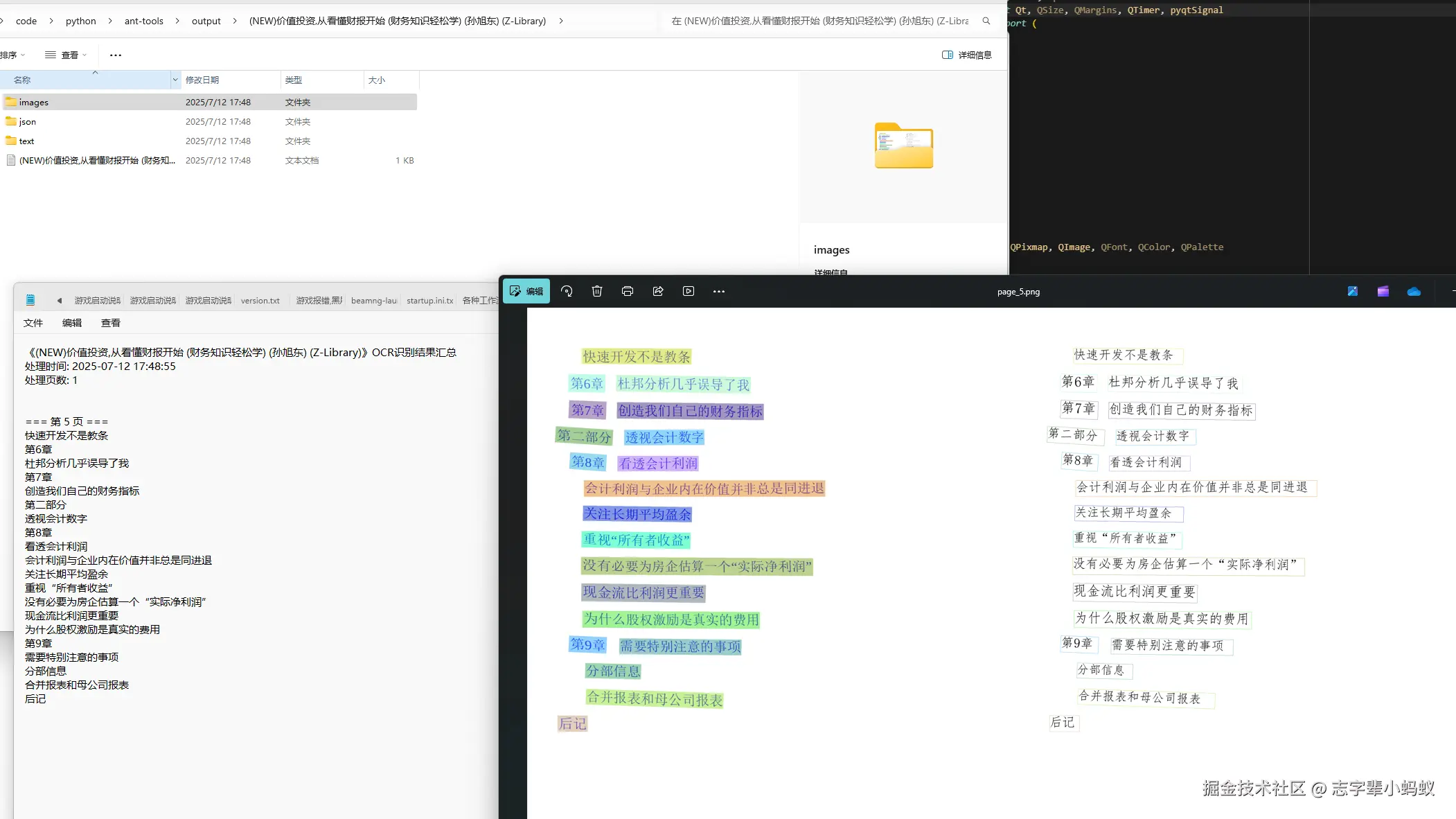
使用效果 :
四. 使用时的一些注意事项
PaddleOCR 对象的准备
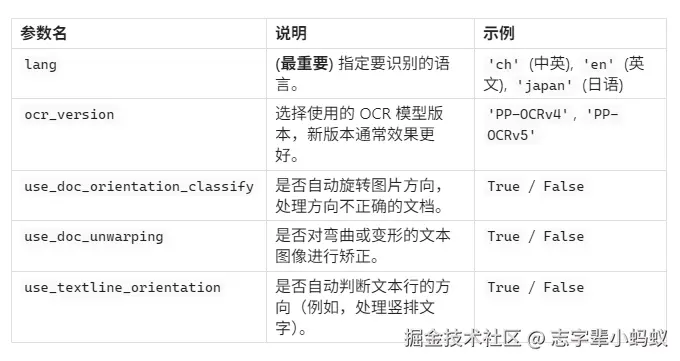
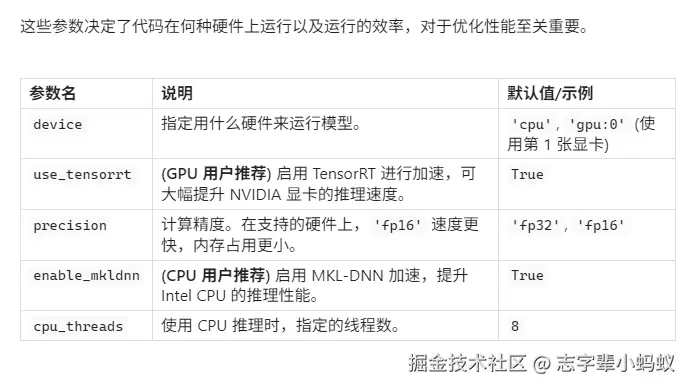
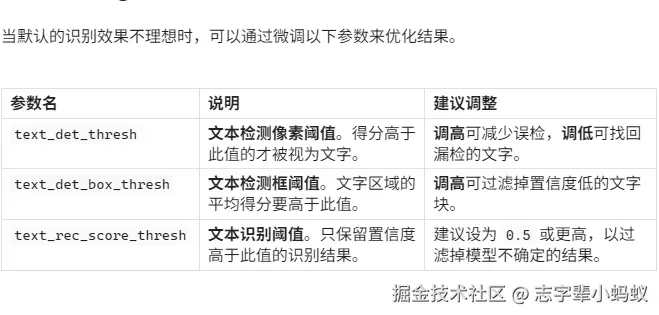
关于请求参数的作用
def predict(
self,
# 待识别的图片,可以是路径、URL或图片数据
input,
# 是否自动旋转图片方向
use_doc_orientation_classify=None,
# 是否自动校正弯曲图片
use_doc_unwarping=None,
# 是否自动判断文本行方向
use_textline_orientation=None,
# 临时修改文本检测模型的最长边限制
text_det_limit_side_len=None,
# 临时修改文本检测的最长边限制类型
text_det_limit_type=None,
# 临时修改文本检测的二值化阈值
text_det_thresh=None,
# 临时修改文本检测的检测框得分阈值
text_det_box_thresh=None,
# 临时修改文本检测的文本框扩大比例
text_det_unclip_ratio=None,
# 临时修改文本识别的置信度阈值
text_rec_score_thresh=None,
# 结果保存格式 (txt, json, pdf, pdf_searchable)
save_format=None,
# 结果保存路径
save_path=None,
# 结果可视化或生成PDF时使用的字体路径
font_path=None,
):
# ... 函数的具体实现逻辑 ...
pass
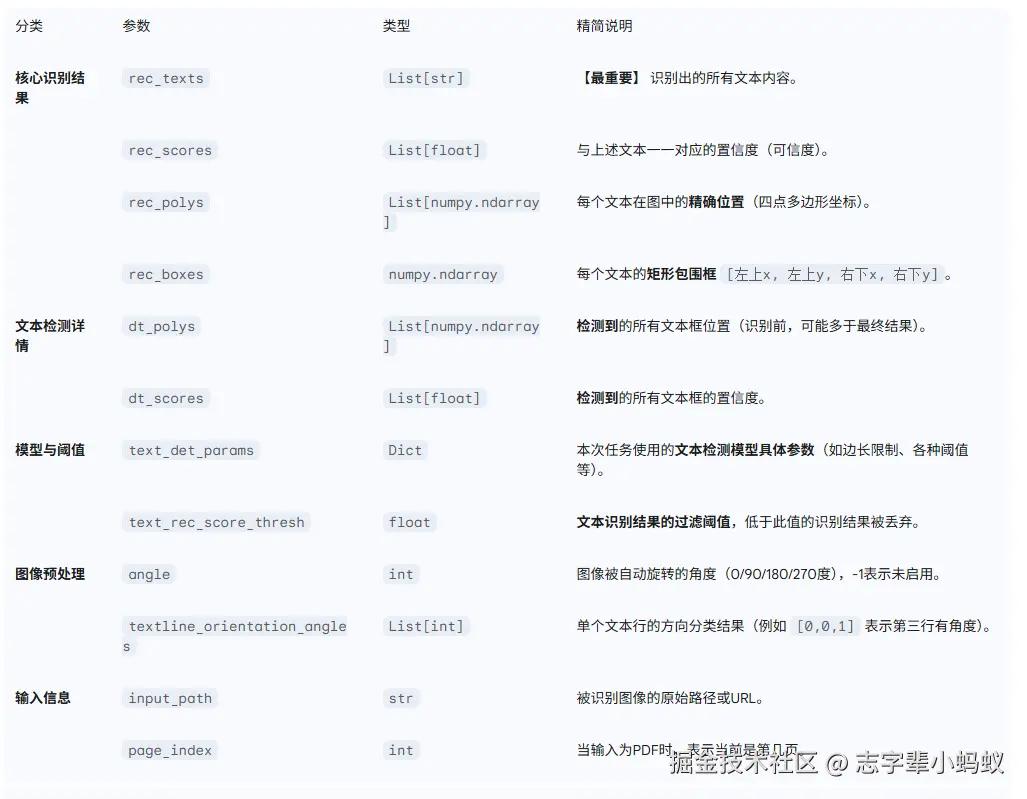
Result 结果
源码 @ gitee.com/antblack/ant-tools/tree/Tools-PDF
以上就是Python调用paddleocr编写一个桌面端PDF识别工具的详细内容,更多关于Python paddleocr识别PDF的资料请关注IT俱乐部其它相关文章!

