前言
大家在使用pandas的时候,大部分可能就是一些匹配关系,主要也就是使用merge函数之类的。
但是有时候在匹配的时候,并不需要使用merge的函数,使用别的函数也是可以做到,今天也就是给大家分享一个找BOSS的代码。
问题
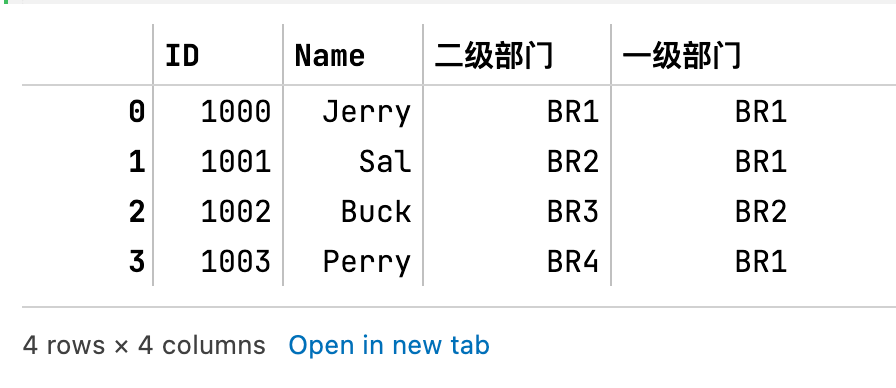
有这样的一个数据,这个数据的第一列是员工的ID,第二列是员工的Name,第三列是这个员工所属的直接部门,第四列代表这个员工所属的上级部门。
那么我要想找到员工的boss应该怎么办?
数据代码如下:
import pandas as pd
import numpy as np
df = pd.DataFrame(np.array([[1000, 'Jerry', 'BR1','BR1'],
[1001, 'Sal', 'BR2', 'BR1'],
[1002, 'Buck', 'BR3', 'BR2'],
[1003, 'Perry','BR4','BR1']]),
columns=['ID', 'Name', '二级部门', '一级部门'])
df
解决方案
很多人可能想到,这样的问题就很简单了,直接使用merge做数据合并的操作。也就是所谓的我自己合并我自己。
这里提供两个方案,使用pandas的map函数或者replace函数就可以优雅的解决我们的难题,代码也是超级简单。
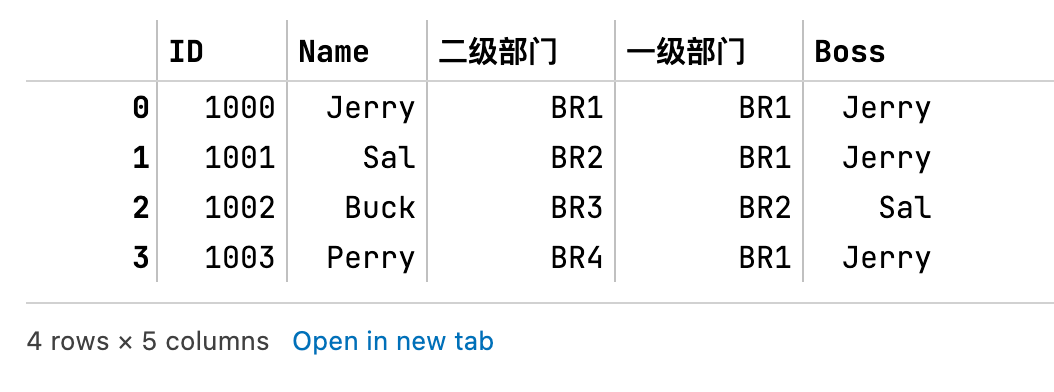
1 使用map函数
df['Boss'] = df['一级部门'].map(df.set_index('二级部门')['Name'])
df
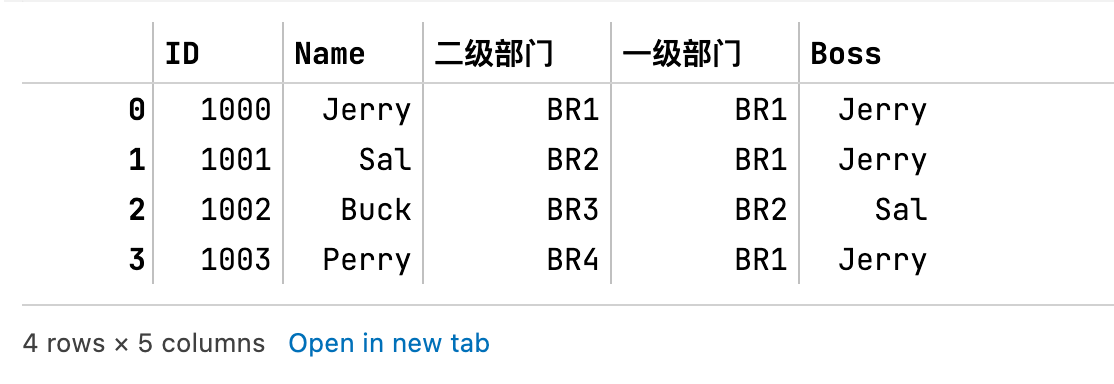
2 使用replace函数
# 重置df数据
df = pd.DataFrame(np.array([[1000, 'Jerry', 'BR1','BR1'],
[1001, 'Sal', 'BR2', 'BR1'],
[1002, 'Buck', 'BR3', 'BR2'],
[1003, 'Perry','BR4','BR1']]),
columns=['ID', 'Name', '二级部门', '一级部门'])
# 使用repalce函数
df['Boss'] = df['一级部门'].replace(df.set_index('二级部门')['Name'])
df
函数介绍
map函数介绍
根据输入关系映射对应Series的值。
说白了,map函数就是将一列数据(DataFrame的一列 或者一个pd.Series)按照一个参考数据(Dict或者是pd.Series或者是一个函数)做数值的映射关系。
下面就是创建了一个df,这个df是只含有一个id列。
然后创建一个索引叫index1,这个索引的值分别对应a, b, c,索引的键分别是100,101,102。
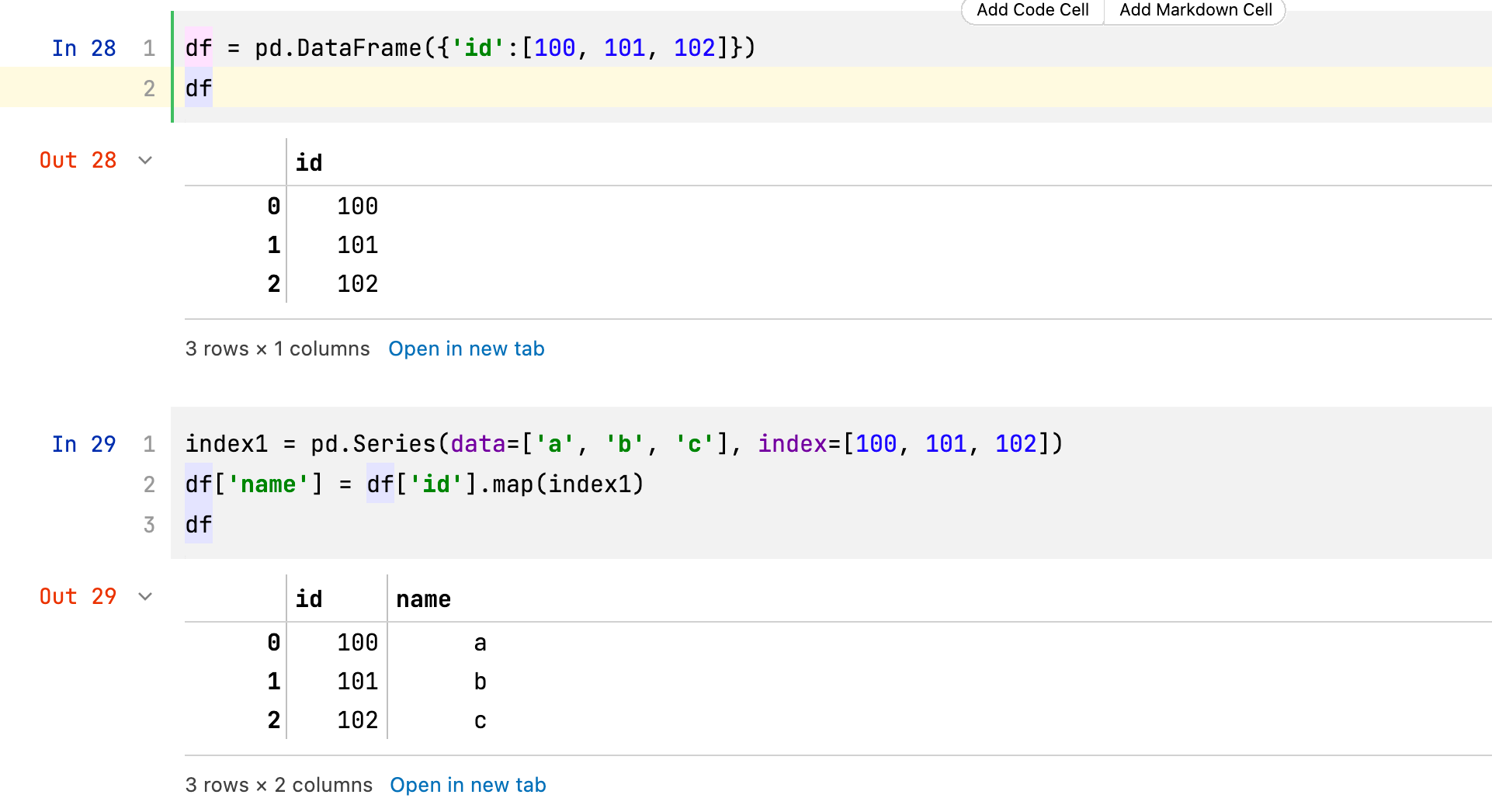
使用map函数就可以帮助df的id列找到对应的名字。
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持IT俱乐部。
参考链接:

