01 解决的问题
1.1 存储下载链接的txt文件
很显然,问题在于IDM已经可以导入txt文件进行批量下载,为什么还需要呢?
第一:IDM对于大批量的下载链接(实际体验大于5000个链接就已经非常卡顿无法移动鼠标和操作IDM)的txt文件是全部导入,即使对于高性能的笔记本也没法抗住;
第二:IDM并没有很好的解决对于文件中断的监测,尤其是大批量 ,而使用自定义的DownloadManager类可以从中断处继续调用IDM下载;
1.2 循环添加下载链接
如果你需要是申请下载链接,然后再利用IDM下载所需文件,那么或许手动操作比较繁琐,这里关于DownloadManager有一些方法可以稍微解决你的问题;
02 代码
2.1 IDM调用命令
从IDM帮助可以获取得到, IDM可以通过CMD命令行调用IDM下载,DownloadManager本质上就是循环调用IDM进行链接文件的下载:
IDM命令行说明:
cmd: idman /s
/s: 开始(start)下载添加IDM中下载队列中的所有文件
cmd: idman /d URL [/p 本地_路径] [/f 本地_文件_名] [/q] [/h] [/n] [/a]
/d URL: 从下载链接url中下载文件
/p 本地_路径: 下载好的文件保存在哪个本地路径(文件夹路径/目录)
/f 本地_文件_名: 下载好的文件输出/保存的文件名称
/q: IDM 将在成功下载之后退出。这个参数只为第一个副本工作
/h: IDM 将在正常下载之后挂起您的连接(下载窗口最小化/隐藏到系统托盘)
/n: IDM不要询问任何问题不要弹窗,安静地/后台地下载
/a: 添加一个指定的文件, 用/d到下载队列, 但是不要开始下载.(即添加一个下载链接到IDM的下载队列中, 可通过/s启动队列的所有下载链接文件的下载)
2.2 DownloadManager类
# @Author : ChaoQiezi
# @Time : 2025/3/31 下午5:12
# @Email : chaoqiezi.one@qq.com
# @FileName: dead_code
"""
This script is used to 用于管理IDM进行批量下载
"""
import os
import time
from pathlib import Path
import json
from urllib.parse import urlparse
from tqdm import tqdm
from subprocess import call
class DownloadManager:
def __init__(self, out_dir, idm_path, links_path=None, status_path=None, concurrent_downloads=16,
monitor_interval=1):
"""
初始化类
:param out_dir: 下载文件的输出目录
:param idm_path: idman.exe的绝对路径, eg: "D:SoftwaresIDMInternet Download ManagerIDMan.exe"
:param links_path: 存储下载链接的txt文件(一行一个下载链接)
:param status_path: 存储结构化下载链接的json文件(用于存储下载链接和状态的json文件)
:param concurrent_downloads: 同时下载文件数量
:param monitor_interval: 监测下载事件的时间间隔,对于大文件:监测时间可适当延长
"""
# 存储下载状态的json文件
if status_path is None:
status_path = os.path.join(Path(__file__).parent, 'links_status.json')
self.status_path = status_path
# 下载文件的输出路径
if not os.path.exists(out_dir):
os.makedirs(out_dir)
self.out_dir = out_dir
# 下载状态
self.downloading_links = list()
self.pending_links = list()
self.completed_links = list()
self.links = list()
self.pbar = None # 下载进度条, 执行self.download()时触发
# 下载参数
self.idm_path = idm_path # IDM软件的绝对路径
self.concurrent_downloads = concurrent_downloads # 同时下载文件数量(并发量)
self.monitor_interval = monitor_interval # 监测下载事件的时间间隔, 单位:秒/s
self.downloaded_count = len(self.completed_links) # 已下载数
self.remaining_downloads = len(self.links) - self.downloaded_count # 未下载数
self.link_count = len(self.links)
self.bar_format = "{desc}: {percentage:.0f}%|{bar}| [{n_fmt}/{total_fmt}] [已用时间:{elapsed}, 剩余时间:{remaining}, {postfix}]"
# 初始化下载状态
if links_path is not None: # 将存储下载链接的txt文件存储为结构化json文件
self._init_save(links_path)
elif os.path.exists(self.status_path):
with open(self.status_path, 'r') as f:
links_status = json.load(f)
self.downloading_links = links_status['downloading_links']
self.pending_links = links_status['pending_links']
self.completed_links = links_status['completed_links']
self.links = links_status['links']
self._update()
else:
self._update()
def _init_save(self, links_path):
"""
从存储下载链接的txt文件中初始化下载链接及其下载状态等参数
:param links_path: 存储下载链接的txt文件
:return: None
"""
with open(links_path, 'r') as f:
urls = []
for line in f:
if not line.startswith('http'):
continue
urls.append({
'url': line.rstrip('n'),
'filename': self._get_filename(line.rstrip('n'))
})
self.links = urls.copy()
self.pending_links = urls.copy()
"""
# 必须使用copy(), 否则后续对self.pending_links中元素操作, 会影响self.links的元素, 因为二者本质上都是指向(id相同)同一个列表urls
self.links = urls
self.pending_links = urls
"""
self._update()
def _update(self, downloading_links=None, pending_links=None, completed_links=None, links=None):
"""更新下载链接的状态位置并保存"""
if downloading_links is None:
downloading_links = self.downloading_links
if pending_links is None:
pending_links = self.pending_links
if completed_links is None:
completed_links = self.completed_links
if links is None:
links = self.links
self.downloaded_count = len(self.completed_links)
self.remaining_downloads = len(self.links) - self.downloaded_count
self.link_count = len(self.links)
with open(self.status_path, 'w') as f:
json.dump({
'downloading_links': downloading_links,
'pending_links': pending_links,
'completed_links': completed_links,
'links': links
}, f, indent=4) # indent=4表示缩进为4,让排版更美观
def add_link(self, link: str, filename=None):
"""
添加新链接
:param link: 需要添加的一个链接
:param filename: 该链接对应下载文件的输出文件名
:return: None
"""
# 结构化下载链接
new_item = self._generate_item(link, filename)
# 添加下载链接到links
if new_item not in self.links:
self.links.append(new_item)
self.pending_links.append(new_item)
self._update()
def _get_filename(self, url):
"""获取下载链接url对应的默认文件名称"""
return os.path.basename(urlparse(url).path)
def _generate_item(self, link: str, filename=None):
"""基于下载链接生成item"""
item = {
'url': link,
}
if filename is not None:
item['filename'] = filename
else:
item['filename'] = self._get_filename(link)
return item
def _init_download(self):
"""
初始化下载链接的状态并启动下载
:return:
"""
# self.links复制一份到pending_links中
self.pending_links = self.links.copy()
self._pending2downloading() # 将中的链接添加到去
def download(self):
"""
对此前加入的所有url进行下载
:return:
"""
try:
self.pbar = tqdm(total=self.link_count, desc='下载', bar_format=self.bar_format, colour='blue')
self._init_download()
self._monitor()
except KeyboardInterrupt:
print('您已中断下载程序; 下次下载将继续从({}/{})处下载...'.format(self.downloaded_count, self.link_count))
except Exception as e:
print('下载异常错误: {};n下次下载将继续从({}/{})处下载...'.format(e, self.downloaded_count, self.link_count))
finally:
self._update() # 无论是否发生异常, 最后都必须保存当前下载状态, 以备下次下载继续从断开处进行
exit(1) # 错误退出
def download_single(self, url, filename=None, wait_time=None):
"""
对输入的单个url进行下载, 最好不要与download()方法连用
:param url: 所需下载的文件链接
:param filename: 输出的文件名称
:return:
"""
if filename is None:
filename = self._get_filename(url)
# 判断当前url文件是否已经下载
out_path = os.path.join(self.out_dir, filename)
if os.path.exists(out_path):
if wait_time is not None:
return wait_time
call([self.idm_path, '/d', url, '/p', self.out_dir, '/f', filename, '/a', '/n'])
call([self.idm_path, '/s'])
if wait_time is not None:
return wait_time + 0
"""
IDM命令行说明:
cmd: idman /s
/s: 开始(start)下载添加IDM中下载队列中的所有文件
cmd: idman /d URL [/p 本地_路径] [/f 本地_文件_名] [/q] [/h] [/n] [/a]
/d URL: 从下载链接url中下载文件
/p 本地_路径: 下载好的文件保存在哪个本地路径(文件夹路径/目录)
/f 本地_文件_名: 下载好的文件输出/保存的文件名称
/q: IDM 将在成功下载之后退出。这个参数只为第一个副本工作
/h: IDM 将在正常下载之后挂起您的连接(下载窗口最小化/隐藏到系统托盘)
/n: IDM不要询问任何问题不要弹窗,安静地/后台地下载
/a: 添加一个指定的文件, 用/d到下载队列, 但是不要开始下载.(即添加一个下载链接到IDM的下载队列中, 可通过/s启动队列的所有下载链接文件的下载)
"""
def _monitor(self):
while True:
for item in self.downloading_links.copy(): # .copy()是为了防止在循环过程中一边迭代downloading_links一边删除其中元素
self._check_update_download(item)
self._update() # 更新和保存下载状态
self.pbar.refresh() # 更新下载进度条状态
call([self.idm_path, '/s']) # 防止IDM意外停止下载
# 直到等待下载链接和正在下载链接中均无下载链接说明下载完毕.
if not self.pending_links and not self.downloading_links:
self.pbar.close() # 关闭下载进度条
print('所有链接均下载完毕.')
break
time.sleep(self.monitor_interval)
def _check_update_download(self, downloading_item):
"""
检查当前项是否已经下载, 成功下载则更新该项的状态并返回True, 否则不操作并返回False
:param downloading_item: 中的当前项
:return: Bool
"""
out_path = os.path.join(self.out_dir, downloading_item['filename'])
# 检查当前文件是否存在(是否下载)
if os.path.exists(out_path): # 存在(即已经下载过了)
# 更新当前文件的下载状态
self.completed_links.append(downloading_item)
self.downloading_links.remove(downloading_item)
self._update_pbar(downloading_item['filename']) # 更新下载进度条
# print('文件: {} - 下载完成({}/{})'.format(downloading_item['filename'], len(self.completed_links), len(self.links)))
# 从中取链接到中(如果pending_links中还有链接)
if self.pending_links:
self._pending2downloading() # 取中的链接添加到中
return True
return False
def _download(self, item):
self.download_single(item['url'], item['filename'])
def _pending2downloading(self):
"""
从阻塞的中取链接中,若所取链接已经下载则跳过
:return:
"""
for item in self.pending_links.copy():
out_path = os.path.join(self.out_dir, item['filename'])
# 判断当前下载链接是否已经被下载
if os.path.exists(out_path): # 若当前链接已经下载, 跳过下载并更新其状态
self.pending_links.remove(item)
self.completed_links.append(item)
self._update_pbar(item['filename'])
continue
elif self.downloading_links.__len__()
2.3 基本使用
如果对于类和调用不太了解,使用前请参照下面步骤进行操作:
- 将上述代码复制在一个空的Python文件中,重命名为
DownloadManager.py; - 在
DownloadManager.py所在目录/文件夹下载新建一个.py文件(不妨命名为links_download.py),用于下载文件 - 运行
links_download.py如果未指定下载状态文件的存储路径,会在同目录下生成links_status.json,在下载没有完成时不要删除该文件
2.3.1 下载链接的txt文件的批量下载
from links_download import DownloadManager out_dir = r'E:MyTEMP' idm_path = r"D:SoftwaresIDMInternet Download ManagerIDMan.exe" links_path = r'F:PyProJectGPPResourcesMyTEMPlinks.txt' downloader = DownloadManager(out_dir, idm_path=idm_path, links_path=links_path) downloader.download()
下载界面如下,IDM是静默下载的,需要查看手动打开IDM即可:
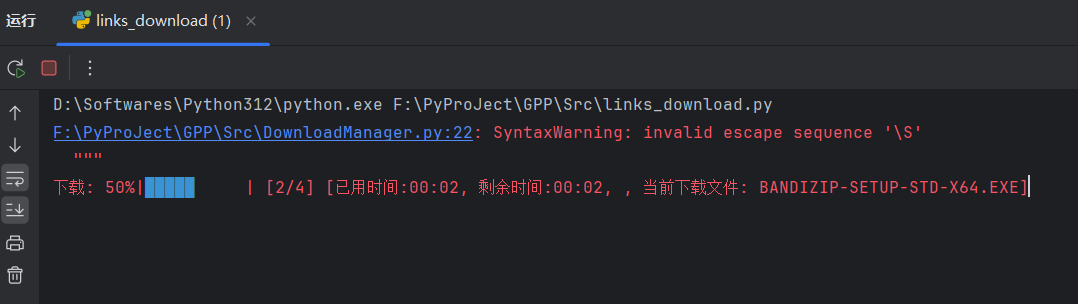
2.3.2 单个文件下载
from DownloadManager import DownloadManager out_dir = r'E:MyTEMPgo' idm_path = r"D:SoftwaresIDMInternet Download ManagerIDMan.exe" url = 'https://bandisoft.okconnect.cn/bandizip/BANDIZIP-SETUP-STD-X64.EXE' downloader = DownloadManager(out_dir, idm_path=idm_path) downloader.add_link(url, 'xxx.exe') # 若不指定输出文件名称则链接指定的默认名称 downloader.download()
注意: DownloadManager(out_dir, idm_path=idm_path)中输出路径out_dir和IDM软件的绝对路径idm_path一定在最初始化的时候就要指定,否则报错.
2.4 示例
2.4.1 批量下载ERA5文件(循环添加下载链接)
注意,下面两个示例py文件代码,其中
import Configfrom Config import my_key, my_urlfrom Src.utils import generate_request, DownloadManager这是自定义模块,请参考源码中的正文部分即可,对于引用这部分代码或者方法请忽略或者替换.
# @Author : ChaoQiezi
# @Time : 2025/3/27 上午10:56
# @Email : chaoqiezi.one@qq.com
# @FileName: era5_download_idm
"""
This script is used to 通过IDM多线程下载ERA5数据集
正常下载是通过cdsapi模块进行era5数据集的下载,
但是cdsapi本身下载有限制, 特别是从国内进行下载, 通过IDM多线程下载可以将原先的200KB/S提高至5~10MB/S,
极大提高下载速度.
计划方案
- 需要限制下载文件数量(文件下载数量过多, 全部加载到IDM中可能导致IDM卡死, 亦或者由于下载时间过长导致末端请求的下载链接过期)
- 定期检查下载好的文件(由于网络异常等原因,导致可能文件下载异常, 因此需要检查文件是否下载完成)
- 存储下载链接和下载是否完成的json文件
"""
import os
import time
import cdsapi
from datetime import datetime
from dateutil.relativedelta import relativedelta
from tqdm import tqdm
import Config
from Config import my_key, my_url
from Src.utils import generate_request, DownloadManager
# 准备
out_dir = r'G:ERA5' # 输出nc文件的路径(自行修改)
dataset_name = "reanalysis-era5-land" # era5-land再分析数据集名称
start_date = datetime(2000, 1, 1)
end_date = datetime(2010, 12, 31)
var_names = ["2m_temperature", "2m_dewpoint_temperature", "surface_solar_radiation_downwards"]
# 链接cdsapi客户端
c = cdsapi.Client(url=my_url, key=my_key)
out_link_dir = os.path.join(Config.root_dir, 'Resources', 'era5_links_download')
if not os.path.exists(out_link_dir):
os.mkdir(out_link_dir)
# 获取下载链接
rd = relativedelta(end_date, start_date)
months = rd.years * 12 + rd.months + 1 # 计算总共的月份数
for var_index, var_name in enumerate(var_names):
# 初始化当前变量下载的状态
cur_out_dir = os.path.join(out_dir, var_name)
cur_links_filename = 'era5_links_{}_{}_{}.json'.format(var_name,
start_date.strftime('%Y%m%d'), end_date.strftime('%Y%m%d'))
storage_path = os.path.join(Config.Resources_dir, 'era5_links_download', cur_links_filename)
downloader = DownloadManager(cur_out_dir, status_path=storage_path)
wait_time = 0
# 迭代获取当前月份的下载链接
for month in range(months):
cur_date = start_date + relativedelta(months=month) # months参数用于设置增加或减少月份, 而month参数用于设置具体月份
out_filename = '{}_{}_{:02}.nc'.format(var_name, cur_date.year, cur_date.month)
try:
# 判断当前链接是否已经请求(避免重复请求下载浪费时间和请求次数)
add_bool, item = downloader.should_add_link(filename=out_filename)
if add_bool:
# 获取下载请求
request = generate_request(var_name, cur_date)
cur_url = c.retrieve(dataset_name, request).location
# 添加下载链接
downloader.add_link(cur_url, out_filename)
item = downloader._generate_item(cur_url, out_filename)
print('已添加下载链接({}/{}): {}-{}-{:02}'.format(month+1 + 132 * var_index, months * len(var_names), var_name, cur_date.year, cur_date.month))
if cur_date.month == 8 and cur_date.year == 2010:
print(123)
wait_time = downloader.download_single(item['url'], item['filename'], wait_time=wait_time)
print('正在下载: {}'.format(item['filename']))
if (month + 1) % 12 == 0:
print('等待中({}s)...'.format(wait_time))
time.sleep(wait_time)
wait_time = 0
# 每隔12个月利用cdsapi模块获取下载请求并开始下载, 避免长时间获取下载请求达到限制或者下载请求过期.
except Exception as e:
print('当前下载{}错误: {}'.format(out_filename, e))
finally: # 无论是否发生错误, 都进行下一次循环的下载
continue
2.4.2 批量下载ERA5文件(txt文件下载)
# @Author : ChaoQiezi # @Time : 2025/3/31 上午11:00 # @Email : chaoqiezi.one@qq.com # @FileName: nasa_download_idm """ This script is used to 测试NASA相关数据的下载 """ import os import cdsapi from datetime import datetime from dateutil.relativedelta import relativedelta import Config from Config import my_key, my_url from Src.utils import generate_request, DownloadManager links_path = r'F:PyProJectGPPResourcesMyTEMPnasa_links.txt' downloader = DownloadManager(out_dir=r'F:PyProJectGPPResourcesMyTEMPnasa', links_path=links_path, monitor_interval=10) downloader.download()
2.5 使用说明
暂时没有时间对类做太多说明,可以自行探索和优化代码
到此这篇关于Python调用IDM进行批量下载的实现的文章就介绍到这了,更多相关Python调用IDM批量下载内容请搜索IT俱乐部以前的文章或继续浏览下面的相关文章希望大家以后多多支持IT俱乐部!

