在数据分析和处理的过程中,尤其是在使用 SQL 进行查询时,排名函数(Ranking Functions)是一个非常重要的工具。Apache Hive 和其他数据库系统都提供了一些排名函数,常见的包括 ROW_NUMBER()、RANK() 和 DENSE_RANK()。虽然这三个函数都可以用于为结果集中的行分配一个排名,但它们的工作原理和返回结果却各不相同。本文将深入探讨这三个函数的区别、使用场景以及实例演示。
ROW_NUMBER()、RANK() 和 DENSE_RANK()是排名函数,也叫分组排序函数。即可以对查询结果集进行分组后进行排序,对结果集的每一行分配一个编号。例如:对考试成绩按科目进行分组,然后按分数排序,获取前5名。
ROW_NUMBER()、RANK() 和 DENSE_RANK()这三个函数在mysql8.0、hive、oracle都是支持的
一、函数定义
1.1、ROW_NUMBER()
ROW_NUMBER() 函数用于为结果集中的每一行分配一个唯一的序号。无论是否存在重复值,ROW_NUMBER() 返回的序号都是连续的。这个函数常用于需要唯一行号的场景。
基本语法:
ROW_NUMBER() OVER (PARTITION BY column1 ORDER BY column2)
- PARTITION BY:指定如何将结果集分组。
- ORDER BY:指定每个分组内的排序规则。
1.2、RANK()
RANK() 函数与 ROW_NUMBER() 类似,也用于对结果集中的行进行排名,但在处理重复值时表现不同。RANK() 会为相同的值分配相同的排名,并在随后排名中跳过相应的名次。
基本语法:
RANK() OVER (PARTITION BY column1 ORDER BY column2)
1.3、DENSE_RANK()
DENSE_RANK() 函数也是用于排名的,其与 RANK() 的主要区别在于处理重复值时的行为。DENSE_RANK() 为相同的值分配相同的排名,但不会跳过名次。
基本语法:
DENSE_RANK() OVER (PARTITION BY column1 ORDER BY column2)
1.4、row_number()、rank() 和 dense_rank() 的区别
- ROW_NUMBER():为每一行分配一个唯一的行号。即使有重复值,返回的行号也是唯一且连续的。
- RANK():为相同的值分配相同的排名,但在后续排名中会跳过相应的名次。例如,如果有两个并列第一的记录,则下一个记录的排名为第三。
- DENSE_RANK():与 RANK() 类似,给相同的值分配相同的排名,但后续排名不会跳过。相同的值后面的排名是紧接着的下一个值。
二、使用示例
结合示例来看一下三者之间的区别,以下sql基于MySql8.0进行讲解。
建表语句:
create table test(
id varchar(10) NOT NULL,
`name` varchar(10) NULL,
age varchar(10) NULL,
salary int NULL
);
-- 数据是每个人不同年龄段的薪资数据
insert into test(id,`name`,age,salary) values(1,'张三',24,15000);
insert into test(id,`name`,age,salary) values(2,'李四',22,8000);
insert into test(id,`name`,age,salary) values(3,'王五',20,6500);
insert into test(id,`name`,age,salary) values(4,'赵六',23,15000);
insert into test(id,`name`,age,salary) values(5,'孙七',22,8000);
insert into test(id,`name`,age,salary) values(6,'周八',21,7500);
表数据:
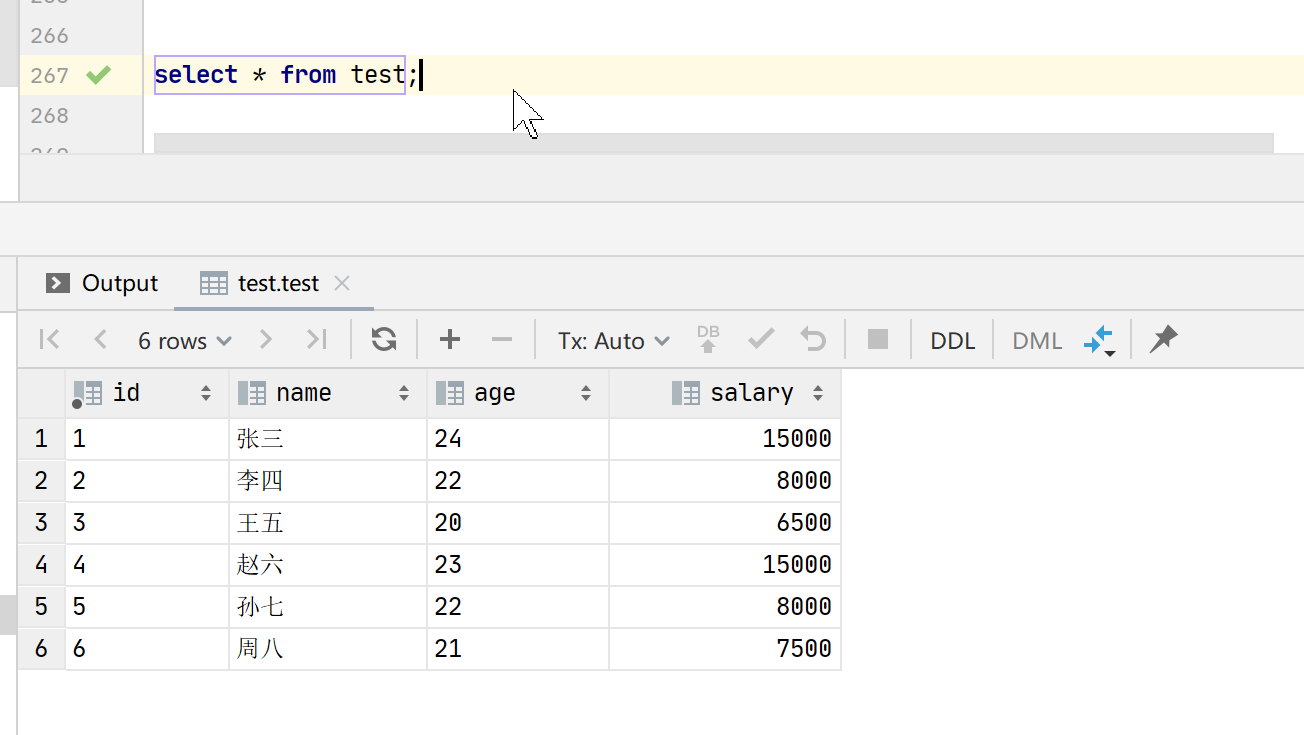
以下是使用这三个函数的 SQL 查询示例:
SELECT id, name, salary,
ROW_NUMBER() OVER (ORDER BY salary DESC) AS rn,
RANK() OVER (ORDER BY salary DESC) AS `rank`,
DENSE_RANK() OVER (ORDER BY salary DESC) AS `dense_rank`
FROM test;
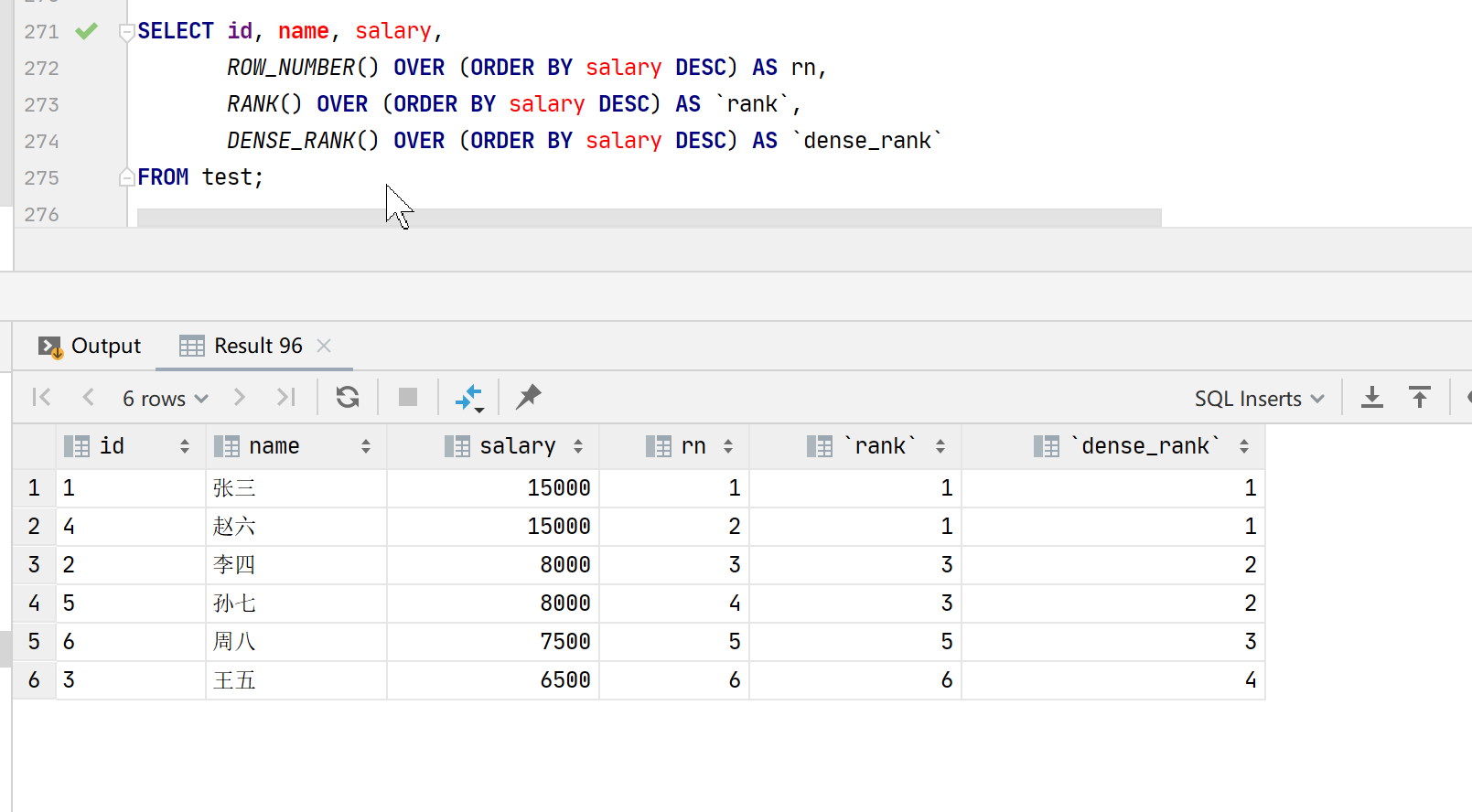
注意:以上sql只使用了order by进行排序,并没有使用partition by进行分组,所以默认是同一组,然后组内进行排名。
从上表可以看出:
- ROW_NUMBER(): 会为每一行数据分配唯一连续的编号,不会因为排名相同而分配相同的编号。
- RANK(): 若排名相同则分配相同的编号,并在随后排名中跳过相应的名次。
- DENSE_RANK(): 若排名相同则分配相同的编号,并在随后排名中不跳过相应的名次。
三、总结
在数据分析中,ROW_NUMBER()、RANK() 和 DENSE_RANK() 是非常有用的工具。它们可以帮助用户快速对数据进行排名和分类分析。虽然这三种函数的作用相似,但因其在处理重复值时的行为不同,所以在使用时需要根据具体需求进行选择。
3.1、row_number()、rank() 和 dense_rank() 的区别
- ROW_NUMBER():为每一行分配唯一的行号,适合唯一标识需求。
- RANK():为重复值分配相同的排名,并在后续排名中跳过名次,适合需要处理排名的场景。
- DENSE_RANK():为重复值分配相同的排名,但不跳过名次,适合希望连续排名的场景。
下面表格总结了这三个函数的主要区别:
| 函数 | 特点 | 排名示例 |
|---|---|---|
| ROW_NUMBER | 为每行分配唯一的数字 | 1, 2, 3, 4, … |
| RANK | 相同的值共享相同的排名,排名会跳过数字 | 1, 1, 3, 4, … |
| DENSE_RANK | 相同的值共享相同的排名,不跳过数字 | 1, 1, 2, 3, … |
具体请参考《row_number() over (partition by 分组列 order by 排序列 desc)、row_number() 函数、分组排序函数》、《数据库rank()分组排序函数详解》、《数据库dense_rank() 函数的使用、MySQL之dense_rank()、Hive之dense_rank()函数》
到此这篇关于数据库中row_number()、rank() 和 dense_rank() 的区别的文章就介绍到这了,更多相关row_number() rank() dense_rank()内容请搜索IT俱乐部以前的文章或继续浏览下面的相关文章希望大家以后多多支持IT俱乐部!

